

Auto Generation Of Tests

No more struggling with doubts on your own! Our AI-powered platform is designed to help you resolve your queries quickly and easily. Whether you’re struggling with a difficult concept or need clarification on a particular topic, our platform connects you with the expert assistance you need to succeed instantly. Start using Embibe’s Doubt Resolution solution today!
Millions of students nationwide use Embibe regularly to learn more, practice hard and test themselves to achieve learning outcomes. Throughout this journey, it is expected to stumble upon many questions or doubts. We, hence, have the Doubt Resolution product in place, to ensure that questioning is always encouraged amongst students.
As the name suggests, it is the platform that aims to help solve the doubts of students. While the subject matter experts can offer this help, the volume and the breadth of doubts coming simultaneously in real-time can make it very hard for these experts to get back to every doubt manually. This can, in turn, introduce longer wait times and a sub-optimal user experience.
Tapping the Opportunity
A vast majority of academic content includes information that is hidden in images, equations, and symbols. Extracting semantic information from images and texts is still a domain-dependent and hard task that requires access to large datasets, domain-specific knowledge, and state-of-the-art deep learning approaches for natural language and vision.
Most doubt-resolution products utilise existing corpora of content to provide similar questions or build a system capable of answering questions based on the available context around the question. We, at Embibe, have millions of questions in our question bank. We use state-of-the-art models fine-tuned on our academic corpora to get the contextual information from the question text, and diagrams or figures present in the question.
With the Doubt Resolution product, 93% of queries can be answered automatically without the need for any human Intervention.
Building Doubt Resolution System
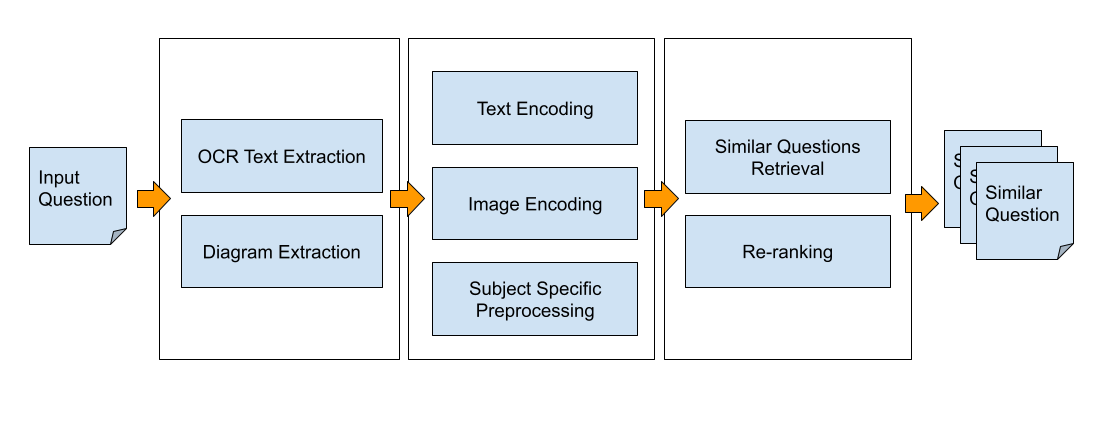
Diagram Extraction:

To be able to help solve the doubt at hand, it is important for us to capture all the details provided around the question. We, hence, introduce a diagram extraction layer to ensure that the extracted diagrams are also considered in computing semantic similarity. The presence of a diagram in an input to the OCR module could confuse it, so we process the image to remove the diagram bounding box, which simplifies it for the OCR processing. Our natively built figure extraction model for academic domain significantly outperforms complex models like YOLOv5 in latency by achieving similar accuracies.
Optical Character Recognition (OCR):

After we extract the figures in the image, we use the OCR layer to extract and parse the text inside the image to be used later. Preprocessing steps like skew correction, removing shadow, enhancing resolution, and detecting blur are done to improve the OCR performance.
Image Encoding:
We use the state of the art computer vision models like ResNet, and EfficientNet to encode the figures into a dense vector that captures the semantic information present in the image such that semantically similar images will be nearer to each other than some different images.
Text Encoding:
We learn dense vector representation by leveraging techniques like triplets loss and mutual information maximization by training the model on our academic corpora, consisting of question texts, answers and their detailed explanations. We leverage pre-trained language models like BERT and T5. Then we use this encoder model to transform the OCR-extracted text into dense vectors, which are further used to retrieve semantically similar questions.
Retrieving Similar Questions:
We compare encoded images and text against all the questions present in our question bank and retrieve top-k similar questions. We also employ techniques to take a weighted similarity if the text and image both are present based on the importance of the image in a question. Performing cosine similarity of dense vectors over millions of records is costly. Hence, we leverage sharding, bucketing, and clustering approaches to make our system low-latent and performant.
Subject Specific Post Processing:
We use subject-specific post-processing techniques, such as handling chemical equations, and math expressions present in the text. Chemical equations and chemical entities present in the text plays an important role in retrieving semantically similar questions.

References:
[1] Raffel, Colin, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. “Exploring the limits of transfer learning with a unified text-to-text transformer.” arXiv preprint arXiv:1910.10683 (2019).
[2] Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[3] Tan, Mingxing, and Quoc Le. “Efficientnet: Rethinking model scaling for convolutional neural networks.” In International Conference on Machine Learning , pp. 6105-6114. PMLR, 20
[4] Faldu, Keyur, Amit Sheth, Prashant Kikani, and Hemang Akabari. “KI-BERT: Infusing Knowledge Context for Better Language and Domain Understanding.” arXiv preprint arXiv:2104.08145 (2021).
[5] Gaur, Manas, Keyur Faldu, and Amit Sheth. “Semantics of the Black-Box: Can knowledge graphs help make deep learning systems more interpretable and explainable?.” IEEE Internet Computing 25, no. 1 (2021): 51-59.
[6] Gaur, Manas, Ankit Desai, Keyur Faldu, and Amit Sheth. “Explainable AI Using Knowledge Graphs.” In ACM CoDS-COMAD Conference. 2020.
[7] Sheth, Amit, Manas Gaur, Kaushik Roy, and Keyur Faldu. “Knowledge-intensive Language Understanding for Explainable AI.” IEEE Internet Computing 25, no. 5 (2021): 19-24.
[8] “#RAISE2020 – Embibe – AI-Powered learning outcomes platform for personalized education”, MyGov India, Oct 2020, https://www.youtube.com/watch?v=kuwFtHgN3qU
[9] Faldu, Keyur, Aditi Avasthi, and Achint Thomas. “Adaptive learning machine for score improvement and parts thereof.” U.S. Patent 10,854,099, issued December 1, 2020.
← Back to AI home


















