

Auto Generation Of Tests

Empower Your Learning with Knowledge Buddy. Our Knowledge Buddy tool is an intelligent chatbot that uses the power of Artificial Intelligence to help students revise their learning and resolve their doubts in real-time. It also answers students’ questions while they engage with learning content, providing them with immediate feedback and support.
At Embibe, we are committed to empowering students’ learning journey. Knowledge Buddy is an Artificial Intelligence chatbot built to help students revise their learnings using question answering and doubt resolution.
Explicit domain knowledge is key to complementing deep learning models for auto-question generation and answering. Emibibe’s Knowledge Graph is the backbone of content intelligence, it has thousands of concepts and competencies inter-connected using more than a million relationships.
Knowledge Buddy is built using conversational artificial intelligence and state-of-the-art language and vision models. It infuses knowledge context from academic knowledge graphs into these deep learning models to create intelligent conversations.
The Knowledge Buddy offers the following capabilities:
- Auto-generates and asks questions based on a student’s learning history to assess the student’s learning outcomes.
- Answers the student’s questions while the student engages with learning content.
- Auto-translate questions and answers in the vernacular language preferred by users.
Examples of Knowledge Buddy’s capabilities are shown in Figure 1.
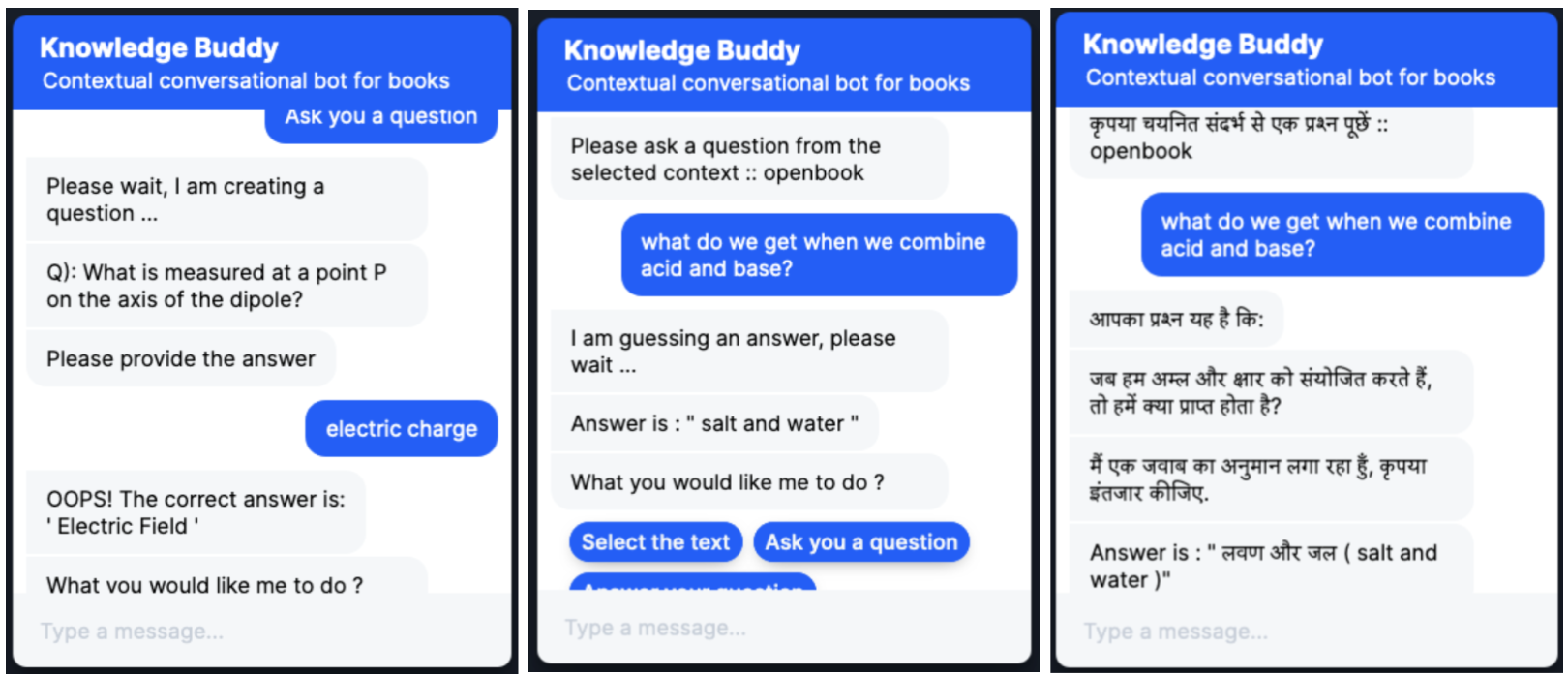
Figure 1: Demonstrating Knowledge Buddy’s Question Generation, Answering and Translation Capabilities
- Question Generation (QG)
The ability to automatically generate questions could bring the opportunity to engage with students and assess their concepts mastery. We have extended state-of-the-art language models like T5, UniLM, etc., and trained them on available research datasets like ARC, DROP, QASC, SciQ, SciTail, SQUAD, HotpotQA, etc., and Embibe-owned datasets. We support multiple types of questions like boolean, span-based, fill-in-the-blanks, multiple choice questions, etc. We leverage knowledge infusion from academic knowledge graphs with architectures like KI-BERT [3]. We also make sure models are better interpretable and explainable with the help of augmenting knowledge graphs [4][6][7]. Our models also generate multi-hop questions with the help of entity-aware attention mechanisms. The Question Generation Model takes learning context as input, prompt for desired question type, and other question type-specific metadata as the input. We use beam search and nucleus sampling methods to generate the questions.
- Question Answering (QA)
Students’ learning journey gets positively impacted when they have an impromptu question-answering capability to engage with. Learning activities for students would be effective when their questions are answered as and when they arise. Knowledge Buddy empowers students to ask questions, which would be answered using question-answering models. Question-answering models are trained by leveraging pre-trained language models like T5, UniLM, etc., and fine-tuned on the research datasets, and Embibe-owned datasets mentioned in the previous sections. Users can ask questions from different context types, such as selected text, a chapter, a book, or a curriculum. Our question-answering system selects the relevant context based on context types using dense vector semantic similarity and invokes a question-answering model to predict the answer. The feedback loop would continuously help our model to get better. Our question-answering model is so advanced that it could auto-crack the NEET entrance exam.
- Translation in Vernacular Languages (VT)
Knowledge Buddy supports multiple languages, and based on the user’s preferences, the complete conversation could be in any of the vernacular languages. It can ask auto-generated questions in any pre-defined language and evaluate answers in the same language. We use a natively developed NMT model that outperforms other off-the-shelf generic translation modes. Currently, we support 11 Indian languages in the chatbot, which includes Hindi, Gujarati, Marathi, Tamil, Telugu, Bengali, Kannada, Assamese, Oriya, Punjabi, and Malayalam. Our natively developed models outperform 3rd party APIs like Google Translate because of the academic domain specificity.
We can see few examples in Table 1 where our translation is better than Google translation:
| English | Google Translation | Knowledge Buddy Translation |
| Which of the following law was given by Einstein? | निम्नलिखित में से कौन सा कानून आइंस्टीन द्वारा दिया गया था? | निम्नलिखित में से कौन सा नियम आइंस्टीन द्वारा दिया गया था: |
| Which one of the following is not alkaline earth metal? | निम्नलिखित में से कौन क्षारीय पृथ्वी धातु नहीं है? | निम्नलिखित में से कौन सा क्षारीय मृदा धातु नहीं है? |
| Endogenous antigens are produced by intra-cellular bacteria within a host cell. | अंतर्जात प्रतिजन एक मेजबान कोशिका के भीतर इंट्रा-सेलुलर बैक्टीरिया द्वारा निर्मित होते हैं। | अंतर्जात प्रतिजन एक परपोषी कोशिका के भीतर अंत: कोशिकीय जीवाणु द्वारा उत्पन्न किए जाते हैं। |
Table 1: Examples Demonstrating Embibe’s Translation Capabilities
In summary, the conversational AI chatbot Knowledge Buddy could potentially impact a student’s learning journey by helping deliver learning outcomes. It could help students after every learning session, where they could ask questions and resolve their doubts in their native languages. Knowledge Buddy is powered by our NLU platform Medhas, which brings domain knowledge infusion, interpretability and explainability as core underlying principles [3][4][6][7][8].
References:
[1] Raffel, Colin, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. “Exploring the limits of transfer learning with a unified text-to-text transformer.” arXiv preprint arXiv:1910.10683 (2019).
[2] Dong, Li, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. “Unified language model pre-training for natural language understanding and generation.” arXiv preprint arXiv:1905.03197 (2019).
[3] Faldu, Keyur, Amit Sheth, Prashant Kikani, and Hemang Akabari. “KI-BERT: Infusing Knowledge Context for Better Language and Domain Understanding.” arXiv preprint arXiv:2104.08145 (2021).
[4] Gaur, Manas, Keyur Faldu, and Amit Sheth. “Semantics of the Black-Box: Can knowledge graphs help make deep learning systems more interpretable and explainable?.” IEEE Internet Computing 25, no. 1 (2021): 51-59.
[5] Zhu, Fengbin, Wenqiang Lei, Chao Wang, Jianming Zheng, Soujanya Poria, and Tat-Seng Chua. “Retrieving and reading: A comprehensive survey on open-domain question answering.” arXiv preprint arXiv:2101.00774 (2021).
[6] Gaur, Manas, Ankit Desai, Keyur Faldu, and Amit Sheth. “Explainable AI Using Knowledge Graphs.” In ACM CoDS-COMAD Conference. 2020.
[7] Sheth, Amit, Manas Gaur, Kaushik Roy, and Keyur Faldu. “Knowledge-intensive Language Understanding for Explainable AI.” IEEE Internet Computing 25, no. 5 (2021): 19-24.
[8] “[Tutorial] Explainable AI using Knowledge Graphs”, YouTube, ACM SIGKDD India Chapter, Jan 2021, https://www.youtube.com/watch?v=f1sahXYDjRI
[9] “#RAISE2020 – Embibe – AI-Powered learning outcomes platform for personalized education”, MyGov India, Oct 2020, https://www.youtube.com/watch?v=kuwFtHgN3qU
← Back to AI home


















