

Auto Generation Of Tests

Our innovative tool, MetaTags Ranker, is designed specifically for subject matter experts, providing them with comprehensive suggestions for tagging any given question’s subject, unit, chapter, topic, and concept. This powerful tool also offers suggestions for the question’s difficulty level, ideal time, and bloom level, making creating high-quality content that meets students’ goals easier than ever.
In the field of Education Technology, one of the important tasks is to make content accessible and discoverable for all users. In order to do that, companies employ human annotators or subject matter experts to tag content with relevant tags aligned with the product’s overall user experience.
Embibe’s Knowledge Graph has 74,000+ nodes, each representing a discrete unit of knowledge. Additionally, there are 1,89,380 interconnections and 2,15,062 competencies. As the content is expanded over thousands of exams across hundreds of syllabi, the process of tagging becomes more expensive and time-consuming. Furthermore, human bias always creeps in when manual tagging of a dataset happens due to multiple human annotators working on different subsets of the dataset.
MetaTags Ranker aims to alleviate the problems associated with human tagging by replacing the manual process with a human-in-a-loop semi-automatic tagging process. MetaTags Ranker is a tool built for subject matter experts. It provides suggestions for tagging the subject, unit, chapter, topic and concept of any given questions for all goals supported by the Embibe Platform. It also provides suggestions for the difficulty level, ideal time and bloom level of the question.
Let’s illustrate how it works with two examples.
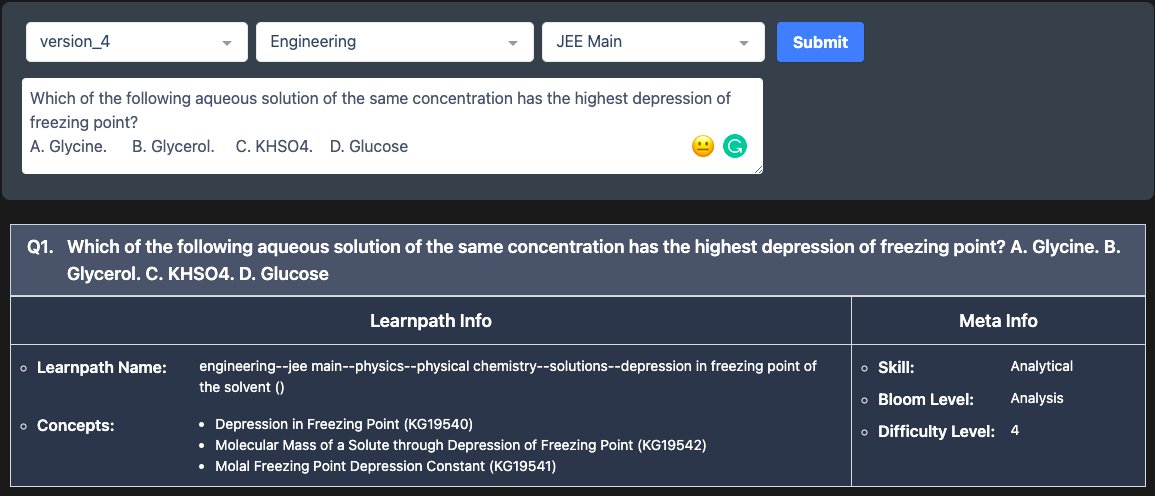
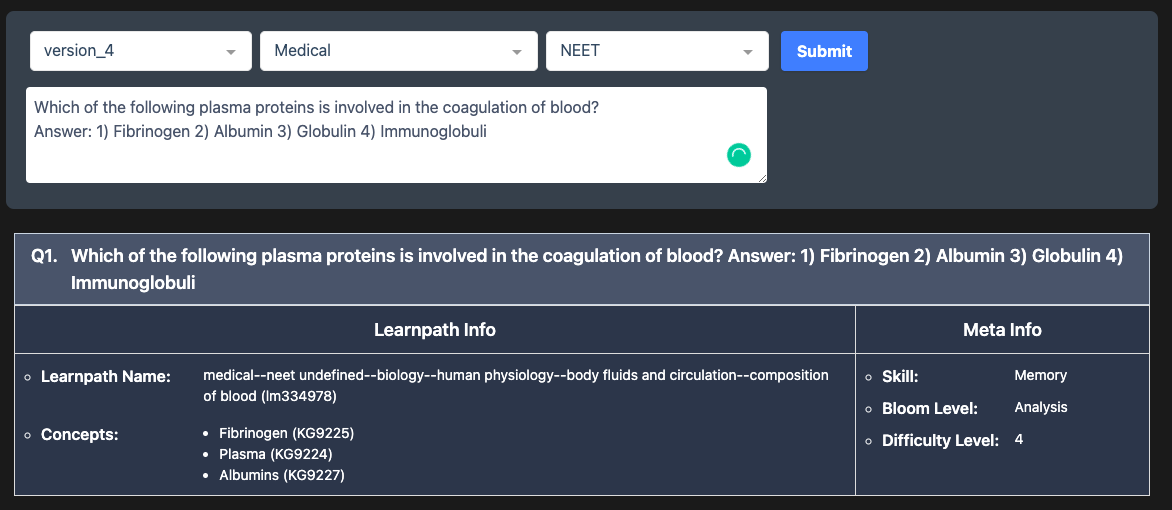
MetaTags Ranker is based on the Extreme Multiclass Classification problem (XMC)[1][2]. For Embibe, there are 74,000+ classes or concepts for any given question. The classes are not mutually exclusive, i.e., concepts are semantically overlapping in nature. The other challenge to XMC is the distribution of the dataset. Not all classes or concepts have a sufficient number of data points, i.e., some classes have too many data points while others have very few, which can lead to classes with few data points being ignored by the model prediction. MetaTags Ranker leverages state-of-the-art deep learning techniques for natural language understanding. It also leverages knowledge graphs in training neural models [3]. The explainable and interpretable predictions by the model help foster academicians’ trust in deploying this capability in production settings [4][5]. Such enriched content empowers auto-test generation [5][7] and the ability to deliver learning outcomes [6].
Meta Tag generator saved thousands of hours of manual tag generation process with AI for Books, questions and learning videos. This also reduced the requirement of subject matter expertise for various grades and subjects. Embibe is also developing speech metatags for video and 3D asset creation.
References:
[1] Chang, Wei-Cheng, Hsiang-Fu Yu, Kai Zhong, Yiming Yang, and Inderjit S. Dhillon. “Taming pretrained transformers for extreme multi-label text classification.” In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 3163-3171. 2020.
[2] Dahiya, Kunal, Deepak Saini, Anshul Mittal, Ankush Shaw, Kushal Dave, Akshay Soni, Himanshu Jain, Sumeet Agarwal, and Manik Varma. “DeepXML: A Deep Extreme Multi-Label Learning Framework Applied to Short Text Documents.” In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, pp. 31-39. 2021.[arXiv]
[3] Faldu, Keyur, Amit Sheth, Prashant Kikani, and Hemang Akabari. “KI-BERT: Infusing Knowledge Context for Better Language and Domain Understanding.” arXiv preprint arXiv:2104.08145 (2021).
[4] Gaur, Manas, Keyur Faldu, and Amit Sheth. “Semantics of the Black-Box: Can knowledge graphs help make deep learning systems more interpretable and explainable?.” IEEE Internet Computing 25, no. 1 (2021): 51-59.
[5] Dhavala, Soma, Chirag Bhatia, Joy Bose, Keyur Faldu, and Aditi Avasthi. “Auto Generation of Diagnostic Assessments and Their Quality Evaluation.” International Educational Data Mining Society (2020).
[6] Faldu, Keyur, Aditi Avasthi, and Achint Thomas. “Adaptive learning machine for score improvement and parts thereof.” U.S. Patent 10,854,099, issued December 1, 2020.
[7] Desai, Nishit, Keyur Faldu, Achint Thomas, and Aditi Avasthi. “System and method for generating an assessment paper and measuring the quality thereof.” U.S. Patent Application 16/684,434, filed October 1, 2020.
← Back to AI home


















