
When we say students can solve unlimited questions on Embibe’s platform, we mean it. Embibe has a large dataset of questions available for students to practice on or to take assessment tests. However, ingesting these questions into the system is tedious and time-consuming.
Historically, this dataset of questions was prepared by human data entry operators who would source questions from various freely available question sets on the internet or via tie-ups with our partner institutions. They would manually type out these questions into a web-based UI. The data is then stored in Embibe’s database and made available to other downstream modules before serving students.
The question input process that the data entry operators would follow typically involved multiple manually intensive steps:
- Identifying the question types,
- Typing out the question body information,
- Formatting mathematical and scientific symbols and notations,
- Identifying images and diagrams in questions,
- Extracting the images at the correct resolution,
- Marking their locations in the questions with image tags,
- Listing out the answer options for single and multiple-answer choice question types,
- Recording the correct answer choice if provided, and
- Recording miscellaneous information like answer explanations, hints, and/or tips to solve the question if present in the source document.
This process is ripe for automation, allowing easy scaling up of content ingestion, thereby reducing costs. As we expand our content to thousands of exams over hundreds of syllabi, automating content and question ingestion has become the need of the hour.
Embibe has developed an in-house ingestion system — a hybrid parser framework that can rapidly adapt to multiple input templates. All modules of the framework are self-contained, which allows for easy enhancements and replacements. When a new template style needs to be ingested, independent developers can rapidly update each module by updating the text pattern matches and parser/extractor scripts.
While this particular step is a manual process, it allows us to achieve an acceptable compromise between content coverage to be ingested vs the speed of rolling out solutions for new ingestion templates.
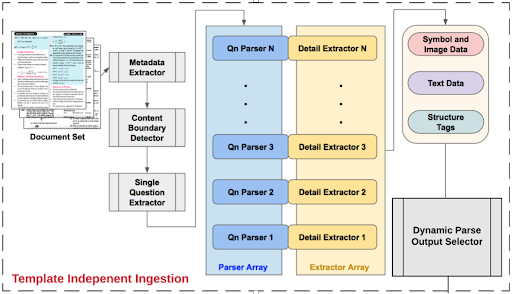
Figure 1: Schematic Overview of Embibe’s Hybrid Parser Framework for Automated Content Ingestion
We measured the framework’s performance recall and precision, as shown in Table 1 below. We can determine a trade-off on acceptable precision rates by controlling for the desired recall rate.
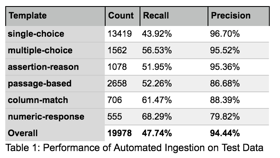
Table 1: Performance of Automated Ingestion on Test Data




















