
As an EdTech platform, allowing students to practice questions on thousands of concepts from the syllabi of hundreds of exams through solver technology is a must. Embibe has invested in enriching questions with explanations and step-by-step solution guides to help students understand how a particular question can be solved. This has been a manual process wherein human subject matter experts solve the questions.
As Embibe’s question dataset grows, relying on manually created solutions is prohibitively expensive. Solver Technology is still a relatively nascent field which has seen some success in generating algorithms to solve text questions in certain specific domains like intermediate-level mathematics.
Embibe is pursuing research in this area to be able to automatically generate answers and step-by-step solutions for the vast number of questions.
Problem Statement
Given a text question in Maths, solve it using solver tech codes and provide a step-by-step solution.
The question can be any freeform question from the student, not necessarily in a particular format. We try to solve it and provide the solution steps.
Approach
Here’s what the whole process looks like:
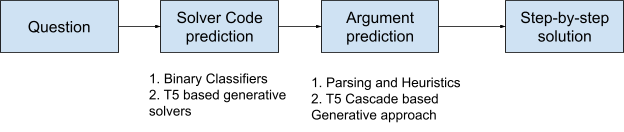
For example,
Here’s a question from the 6th CBSE:
“Write in figures – Two lahk fifty thousand nine hundred thirty-six.”
So, in the first stage, we try to predict the solver code to solve this question, which is “convert_text_to_number”.
In the next stage, we fetch the argument for the predicted solver to evaluate it. So, in this case, the input argument to the solver will be “two lakh fifty thousand nine hundred thirty-six”.
So, we get the full solver:
convert_text_to_number(two lakh fifty thousand nine hundred thirty-six).
Then we evaluate the solver with the argument to get the answer and step-by-step solution, which looks like this:

Let’s elaborate with another example question:
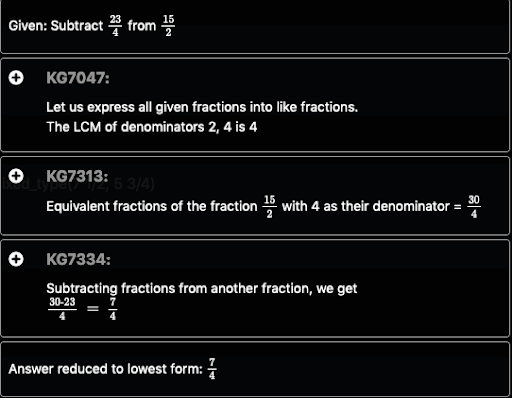
“Mrs Soni bought 7 1/2 litres of milk. Out of this milk, 5 3/4 litres was consumed. How much milk is left with her?”
This can be solved using the “subtract_fractions_mixed_type(7 1/2, 5 3/4)” solver code.
We will get the solution steps like this.
Solution
We can divide the solution into two steps.
- Solver code prediction
- Argument Extraction
In solver code prediction, we try to predict the solver codes using which given math problems can be solved. For instance, in the above example, “subtract_fractions_mixed_type” was the correct solver for solving the given problem. We can use deep learning generative seq2seq models like T5[1] to generate the solver code to solve the problem.
Before moving to the second step, we need 1 sample solver with arguments for each solver code. For example, a sample solver for “subtract_fractions_mixed_type” can be something like “subtract_fractions_mixed_type(1 2/3, 4 5/6)”. How this will be useful, we will explore soon.
Once we get the predicted solver technology code for solving the given problem, we need to fetch the arguments from the question. We can also use generative seq2seq models like T5[1]. Such language models are further extended with knowledge infusion architecture to leverage the semantic relationships captured in the knowledge graphs [3][4]. We can give the problem statement and the sample solver for the predicted solver. And we will get the solver code with actual arguments from the questions from the T5[1] model. So, we will have the solver code with arguments, i.e., “subtract_fractions_mixed_type(7 1/2, 5 3/4)” from the above example.
We can also use other relatively simple methods to fetch the arguments from the question. If we have the data types and samples of the arguments for each solver, which we have in our case, we can try to fetch similar numbers from the question.
This is how we will predict the solver code and fetch the solver arguments from the question. Once we get both of them, we just need to evaluate the solver code to get the correct answer and step-by-step solution.
References
[1] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu. “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”
[2] Amini, Aida, Saadia Gabriel, Peter Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. “MathQA: Towards interpretable math word problem solving with operation-based formalisms.” arXiv preprint arXiv:1905.13319 (2019).
[3] Faldu, Keyur, Amit Sheth, Prashant Kikani, and Hemang Akabari. “KI-BERT: Infusing Knowledge Context for Better Language and Domain Understanding.” arXiv preprint arXiv:2104.08145 (2021).
[4] Gaur, Manas, Keyur Faldu, and Amit Sheth. “Semantics of the Black-Box: Can knowledge graphs help make deep learning systems more interpretable and explainable?.” IEEE Internet Computing 25, no. 1 (2021): 51-59.




















