

Auto Generation Of Tests
As an Ed-tech platform, Embibe curates and manages a huge pool of learning objects which can be served to the students to fulfil their learning requirements. This content pool primarily holds content like videos, explainers, interactive learning elements to educate the user with any academic concept. Also, it contains questions that can be bundled together intelligently to provide gamified practice and test experiences. At Embibe, the user engagement under the practice and test storyline provide us with the crucial academic, behavioural, test-taking, test-level, and user efforts-related specifics that help us drive the user journey and help the student unlock her maximum potential. Given the importance of the practice and test features, we believe in achieving maximum user engagement and retention.
There are various sources through which the pool of questions is prepared: In-house faculties and Subject Matter Experts, Academic Consultants, and various other personnel are involved in this process. The pool also contains the questions from the renowned textbooks and reference materials. Given the involvement of several entities in driving the content pool and the importance of the content in driving the engagement, it becomes necessary to keep track of the content quality. There are various quality-related issues involved with content curation at scale, like Content Duplication, Question Correctness issues, Incomplete Questions, Incorrect Meta Tagging, to name a few. In this article, we will be discussing the Content Duplication issue and the intelligent system being used at the Embibe to tackle it.
The duplicated content (Test/Practice Problems/Questions) in the system is one of the issues that adversely impact user engagement. To understand better, it can be compared with “Facebook or Instagram displaying the same video/image repetitively when a user is busy scrolling through, admit it, it hampers the user engagement, and at worst the user can bow out of the platform for forever.” Similarly, If the same question gets served to the student in the same practice or test sessions, it will certainly contribute to the user drop-off.
At Embibe, to deal with this issue, we have employed a hybrid approach that encapsulates Syntax (edit-distance) based measures and the Deep Learning-based (ResNet-18 Convolutional Neural Network Architecture) dense vector similarities to identify the duplicates for the questions. We utilize Elasticsearch’s (Lucene) core functionalities like the Full-Text Queries on textual content, and the recent script score queries on the Dense Vector Fields to implement the deduplication pipeline. Our learning objects (questions) contain Textual(question text, answer text) as well as Image/Pictorial information (Figures, Diagrams, etc.), and the pipeline considers both of them to identify the exact duplicate counterparts from the content pool. We have also enabled a real-time utility wrapped around the same approach to prevent the creation and ingestion of duplicate questions into the system; it works like a gate-keeping for deduplication.
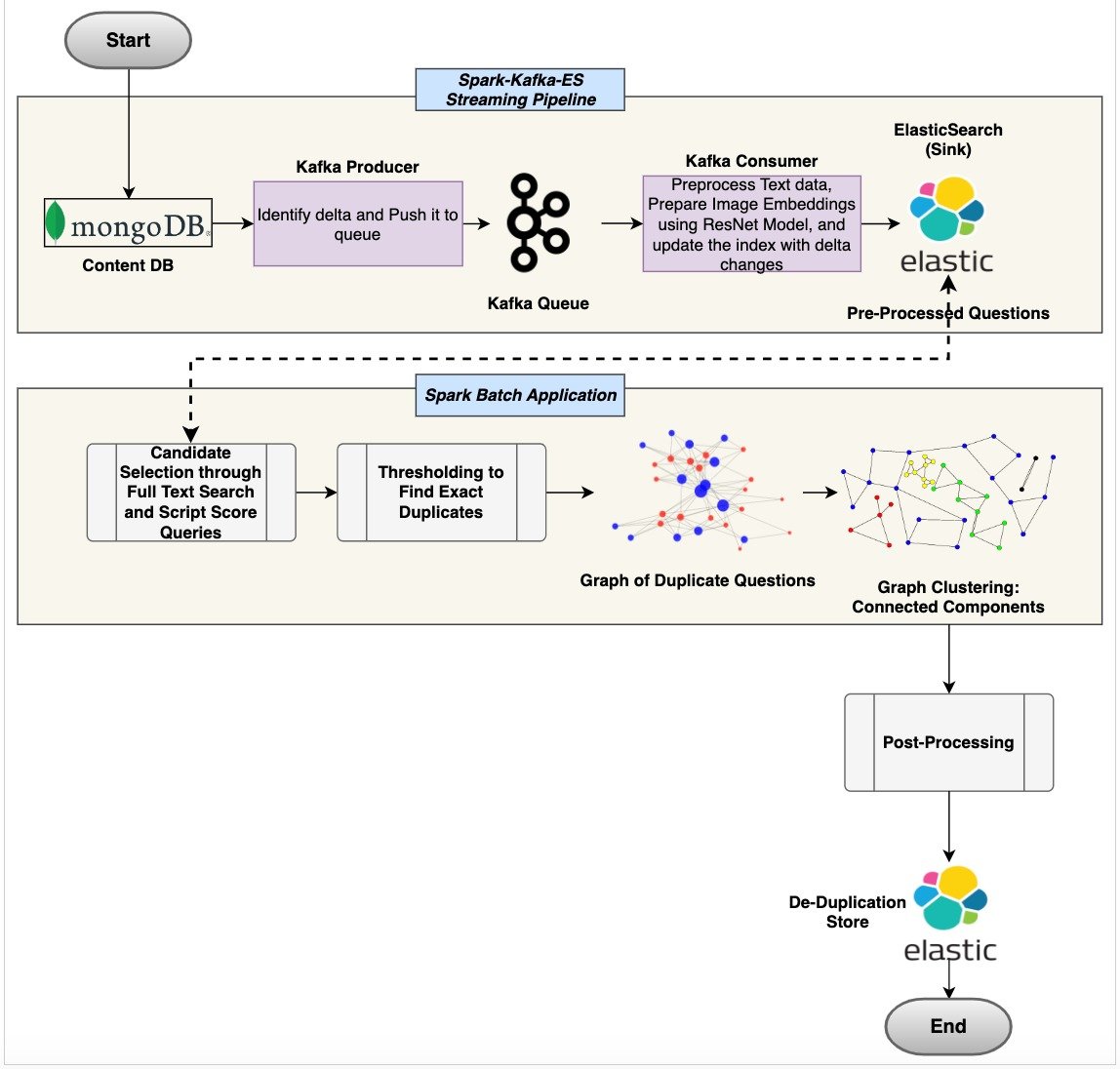
For the content deduplication pipeline, the threshold selection/tuning is at the core of the problem. It helps in separating similar and non-duplicate questions from duplicate ones. Here to identify the appropriate thresholds, we have had taken the help of the Subject Matter Experts in preparing a labelled dataset, where they have been given an anchor question and a list of candidates, from that they were asked to mark the pairs as Duplicate or Not-Duplicate. For candidate generation, top-k candidates were selected from the content pool using Elasticsearch’s Full-Text queries and Script Score queries on the image dense vectors.
Now, to select the right threshold value, a grid search was employed over the different threshold values (range: 0.5 to 1.0, step-size: 0.05) with the maximum accuracy score objective against the labelled dataset. Here top-k candidates were generated for the anchor questions and the accuracy numbers were captured at different threshold values. The similarity score threshold that yields the maximum accuracy was chosen as the final threshold value.
Against the hold-out labelled set, a benchmarking of the mentioned duplicates identification process has been done, the table below mentions the specifics:
| Data | Set Size | Accuracy (marked correctly) |
|---|---|---|
| Labelled Question Pairs containing: Only Text, Text + Image, Only Image | 5114 | 83.1% (4250) |
| Labelled Question Pairs containing: Text + Image, Only Image | 2710 | 80.1% (2193) |
Few changes can be made to improvise the performance of the mentioned pipeline.



















